
1. Introduction
Traditional software development is a waterfall of requirements → design → code → test → deploy. The code that ends up running is usually a product of trial‑and‑error: a human programmer writes a function, tests it, rewrites it, repeats. In recent years, large language models (LLMs) have been used as coding assistants, but their use remains largely reactive – “fill‑in‑the‑blank” or “suggest the next line.”
Reinforcement Development from Feedback (ReDF) flips the script. It treats software creation as a controlled, reward‑driven process in which an autonomous agent – a so‑called agentic developer – proposes, writes, tests, and iterates on code until it satisfies a user’s requirement. The agent learns not from random exploration of a sandbox but from human‑given feedback or automated metrics that explicitly rates or refines its outputs.
ReDF is not a training paradigm that tries to learn a “good code generator” by exposing the model to millions of example code snippets. It is a development paradigm: the agent is directed to complete a task, not to discover patterns in data. The agent’s policy is continually updated to better fulfill human‑described objectives while staying safe, maintainable, and aligned with business goals.
2. Core Concepts
| Term | Definition | Why It Matters |
|---|---|---|
| Agentic Application Development | An autonomous code‑generation agent that follows user intent. | Aligned with user goals. |
| Human‑in‑the‑Loop Alignment | Continuous human feedback shapes the agent’s behavior. | Prevents drift from business values. |
| Metric‑Based Reward | Composite score from tests, linting, performance, etc. | Enforces consistent quality. |
| Specification Engine | Parses natural language into a structured JSON schema. | Bridges human intent and machine logic. |
| Planning Module | Breaks the specification into actionable tasks. | Provides clear roadmap for the agent. |
| Execution Engine | Runs generated code, migrations, tests in a sandbox. | Immediate feedback loop. |
| Feedback Module | Collects human ratings, critiques, and automated metrics. | Keeps the agent aligned with real‑world expectations. |
| Policy Update Layer | Reinforces or corrects the agent’s next action. | Enables continuous learning. |
3. System Architecture
Below is a high‑level view of a sample ReDF pipeline:
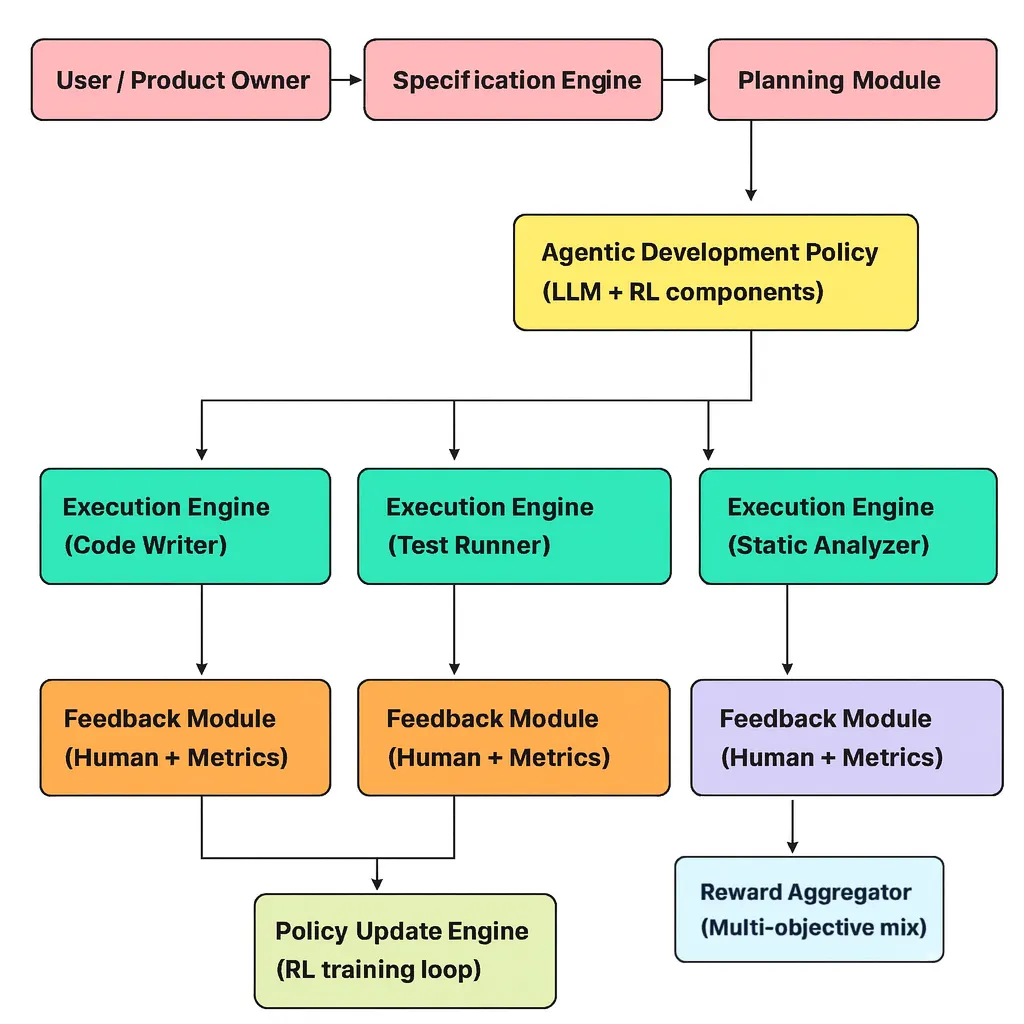
The system is composed of six tightly‑coupled components that together enable autonomous software generation and continuous improvement:
- 1. Specification Engine – Parses a user request (e.g., a natural‑language description or a set of high‑level goals) and emits a structured specification (usually JSON) that enumerates required endpoints, authentication schemes, performance constraints, and other domain constraints.
- 2. Planning Module – Decomposes the high‑level spec into an ordered list of developer actions (e.g., “create endpoint X”, “add unit test Y”, “refactor controller Z”). This is typically a sequence‑to‑sequence model that outputs a low‑level plan.
- 3. Agentic Development Policy – Chooses the exact code fragment, test case, or refactor that will be produced next. It runs inside a reinforcement‑learning loop and is updated continuously via feedback.
- 4. Execution Engine – Carries out the chosen action in a sandboxed environment (writes files, runs unit tests, performs static analysis, etc.). The sandbox guarantees that incomplete or buggy code cannot affect the host system.
- 5. Feedback Module – Collects human ratings or automated metrics after each execution step (e.g., test pass rate, coverage, linting score). These signals are transformed into rewards for the learning loop.
- 6. Policy Update Engine – Aggregates the reward signals and fine‑tunes the development policy using RL techniques such as PPO, REINFORCE, or offline RL. The update can be done online (after every step) or batched (after a full build cycle).
4. Feedback as the Reward Signal
4.1. Types of Feedback
| Type | Example | How it is used |
|---|---|---|
| Explicit Ranking | “Code A is better than Code B” | Creates pairwise preference data for Learning‑to‑Rank style updates. |
| Direct Critique | “Remove the hard‑coded token; use environment variable” | Converted into a corrective action that the agent can replay. |
| Instructional Prompts | “Add unit tests for edge cases” | Augments the specification, leading to new sub‑tasks. |
| Test Case Creation | “Write a test that fails with current code” | Provides a concrete signal that the code is incomplete. |
| Metric Feedback | “Coverage is 70 %, target is 85 %” | Numeric reward proportional to the gap to target. |
| Safe‑ness Flags | “This function might expose data to injection” | Negative reward or constraints to prevent unsafe patterns. |
4.2. Reward Design
An effective reward must capture multiple dimensions of software quality. One possible formulation is:
R = w_func * F + w_quality * Q + w_perf * P + w_sec * S + w_user * UR = w_func * F + w_quality * Q + w_perf * P + w_sec * S + w_user * U- F – Functional correctness (e.g., all unit tests pass; F ∈ [0, 1]).
- Q – Quality & maintainability (static analysis, code style).
- P – Performance (response time, memory usage).
- S – Security (absence of known vulnerability patterns).
- U – User satisfaction (human rating on “does this satisfy the requirement?”).
The weights w_* can be set manually per project or learned via a meta‑RL controller that optimizes for long‑term developer productivity.
4.3. Handling Sparse Rewards
Software development reward signals are often sparse: a test run may only happen after a whole module is built. The following techniques help to mitigate this sparsity:
- Intermediate Rewards – Provide code quality metrics after every file write or commit, giving the agent a denser signal.
- Curriculum Learning – Start training on small, trivial tasks and progressively introduce larger, more complex requirements.
- Monte Carlo Roll‑outs – Simulate the remainder of a development episode to estimate the eventual success of a partial action sequence.
5. Walk‑Through Example
Suppose a product owner says:
Create a CRUD REST API for a Product model. Each product has name, price, in_stock. Use JWT authentication and add a rate limiter of 100 requests per minute.
Step 1 – Specification Engine
{ "model": "Product", "fields": [ "name", "price", "in_stock" ], "endpoints": [ "GET /products", "POST /products", "GET /products/:id", "PUT /products/:id", "DELETE /products/:id" ], "auth": "jwt", "rate_limit": 100 }{
"model": "Product",
"fields": [
"name",
"price",
"in_stock"
],
"endpoints": [
"GET /products",
"POST /products",
"GET /products/:id",
"PUT /products/:id",
"DELETE /products/:id"
],
"auth": "jwt",
"rate_limit": 100
}Step 2 – Planning Module
- Define database schema.
- Scaffold model & migration.
- Implement JWT auth middleware.
- Create CRUD controller.
- Add rate limiter middleware.
- Write unit tests for each endpoint.
- Run integration test.
Step 3 – Agentic Policy (Sample Code Generation)
-- SQL migration for the products table CREATE TABLE products ( id SERIAL PRIMARY KEY, name TEXT NOT NULL, price NUMERIC(10,2) NOT NULL, in_stock INTEGER NOT NULL, created_at TIMESTAMP DEFAULT NOW(), updated_at TIMESTAMP DEFAULT NOW() );
-- SQL migration for the products table
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
price NUMERIC(10,2) NOT NULL,
in_stock INTEGER NOT NULL,
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW()
);
The Execution Engine applies the migration in a sandbox database. The Feedback Module displays the generated file to the human, who rates it 4/5 and suggests that timestamps be stored as TIMESTAMPTZ. The agent receives this critique, updates its policy, and refines the next migration until all steps are satisfied and the final rating is 5/5.
6. Benefits of ReDF
Speed & Efficiency
The agent can parallelize tasks and iterate on specifications in real time.
Consistent Quality
Automated static analysis and metric‑based rewards enforce coding standards.
Rapid Prototyping
Quickly iterate on specs; the agent adapts to changes immediately.
Human‑in‑the‑Loop Alignment
Continuous feedback keeps the agent’s behavior in line with business values.
7. Challenges & Mitigation
| Challenge | Mitigation |
|---|---|
| Hallucination / Wrong Code | Static type checking + immediate unit tests + fail‑fast policy. |
| Safety & Security | Policy constraint layer that forbids insecure patterns. |
| Data Privacy | Sandboxed environment + zero‑knowledge constraints. |
| Scaling to Large Codebases | Chunk‑based planning + hierarchical RL. |
| Human Feedback Fatigue | Active learning + query‑by‑committee. |
8. Collaborative, Self‑Reflective, and Compliant Agents
- 1. Collaborative Multi‑Agent Development – teams of specialized agents (backend, frontend, DevOps) coordinated via a development orchestrator.
- 2. Self‑Reflective Feedback Loops – agents that generate their own test cases and evaluate code quality before seeking human input.
- 3. Human‑Friendly Explanation Generation – the agent can produce a succinct README explaining its design choices, easing hand‑off.
- 4. Integration with CI/CD Pipelines – real‑time deployment after each policy update, allowing rapid feedback cycles.
- 5. Regulatory Compliance Enforcement – agents that enforce GDPR, HIPAA constraints as part of the reward system.
9. Conclusion
Reinforcement Development from Feedback reframes software engineering as a goal‑directed, reward‑driven activity. By equipping an autonomous agent with a structured specification, a planning engine, and a robust feedback loop, we can build applications that directly satisfy user requirements while maintaining high standards of quality, security, and performance.
Rather than learning from the vast sea of existing code, the agent learns and delivering finished software with minimal manual toil. As reinforcement learning advances and feedback interfaces mature, ReDF is poised to become a cornerstone of the next generation of software engineering practices.